Introducing JARR v1
Posted on mer. 13 avril 2016 in JARR
It’s time I (re)present to the world a project I’ve been working on for some time now. It’s a web app that agregate feeds (RSS/Atom) and it let you read most of them inside your browser.
JARR (and it stands for Just Another Rss Reader).
Before going through the details, you can test it by yourself by creating an account on my running instance !
The Stack
The project runs on python3.4 and makes a heavy use of the Flask framework. It’s completed with the SQLAlchemy ORM which allows various SQL database plug. I run my own installation against a PostgreSQL database and it works like a charm. Concerning the UI, I coded the whole thing as a ReactJS one page app.
Let’s have a look:
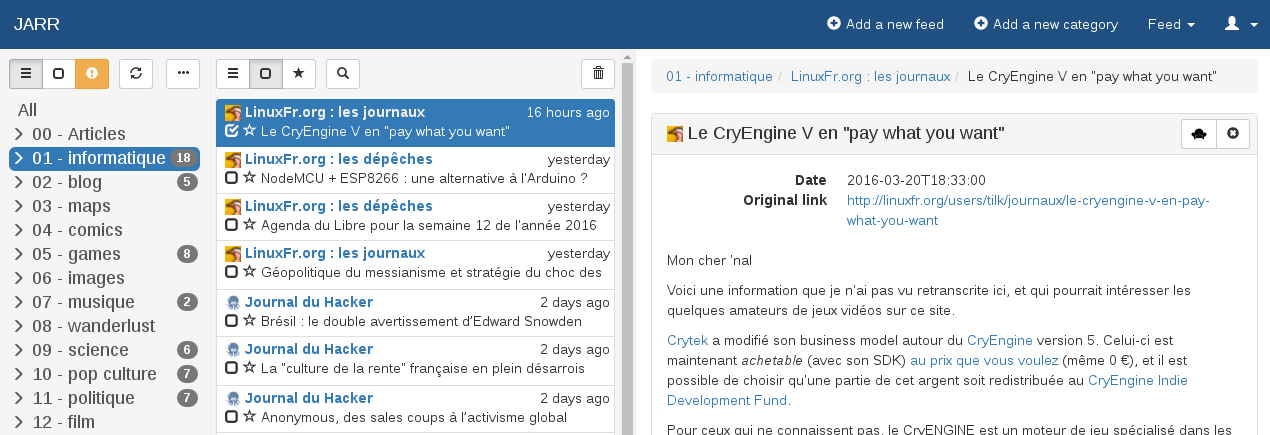
A little tour
- As you can see on the screenshot above, the UI is splited in three columns. From left to right:
- the first one let you see and select your categories and feeds. You can fold categories and display only feeds with unread articles or feeds which have encountered errors.
- the second one is the article list, which will be updated when you select a feed or a category.
- the third and last one is the category, feed, article or article you selected.
As some feeds don’t provide content, the right panel may not be as filled as you can see on the screenshot and you may have to go directly to the source though the link on the feed title in the article list. A better solution has also been implemented, if you have a readability key you provided either at the installation or in your profile, you’ll have a little readability button in the top right corner or your article. Clicking it will retrieve a cleaned version of your content. You can also choose in a feed options to make that retrieving automatic. That’s especially handy for news agregator like HackerNews.
What’s new
I worked a lot on the UI, and it feels pretty done by now. I’ll talk about it a lot below.
I’m working on redoing the install process so it’d be easy to bootstrap the project.
The crawler works pretty fine. The queue system is pretty robust and the whole thing works pretty well, it scales great against huge work loads without consumming to much ressource. The next step for it would be to make it a daemon and make it scale automatically.
Mobile
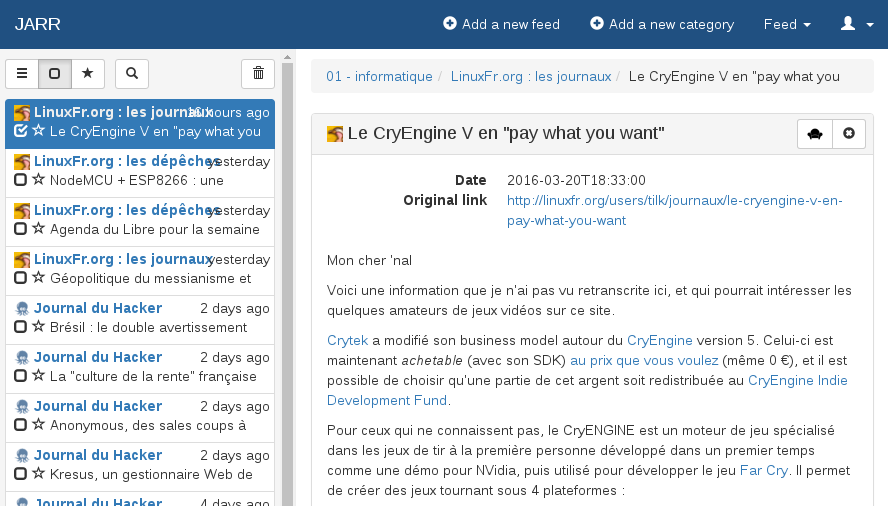
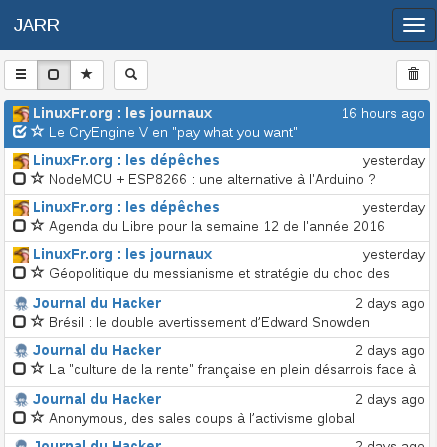
The site is somewhat compatible with smaller device.
Here on tablets :
And on phones :
What’s down the road
Some coming features are listed in the Github milestones. Most of them are obvious UI improvements and utilisability tweaks (as mark an article to be read later on or having a nice integration for well-known feed that misbehave or are poorly formated).
But the main thing I’d like to implement would be an intelligent grouping feature that would regroup articles in clusters. The goal would be to regroup article on the same subject (or pointing to the same resource) so a user wouldn’t be presented with the same news if it appears in multiple feeds. It’s a feature a bit down the road, but definitively coming !
History
The project was initially created by Cédric Bonhomme who I thanks a lot for letting me fiddle with his project. But, as I introduced stuffs to the project that he was less and less easy with, I thought it was time for a full fork.
Conclusion
I’d be happy to see some of you install the project (I worked on the install script so it’s painless :) or try it on my instance. Of course, I’m welcoming all critics and contributions !