L’impact de la sortie de Jarr
Posted on sam. 16 avril 2016 in JARR
J’ai écrit trois quatre mots sur le fait que JARR est passé dans une version propre et stable. C’est la première release publique dirons-nous, et même si c’est sur une niche (linuxfr n’est pas franchement un média de masse), j’ai quand même eu pas mal de retour intéressants (j’ai mis tout ça sur github histoire de retravailler sur tout ça plus tard).
Inscription
À l’heure où j’écris ces lignes 39 nouveaux utilisateurs se sont inscrit sur JARR. La plupart sont des comptes de tests avec seulement un ou deux flux, mais certains on quand même ajouter dans les 20 ou 30 flux.
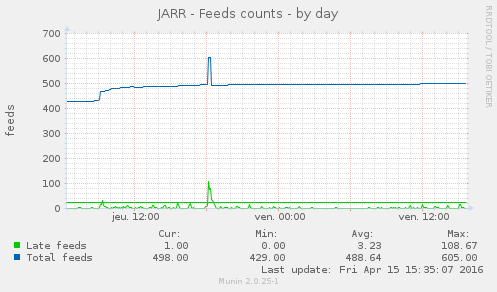
Comme vous pouvez le voir ci-dessus, à peu près 100 feeds ont été ajouté dans les heures qui ont suivies (avec un pic à 200 mais l’utilisateur a sûrement dû détruire son compte après son test).
Ce qu’on peu voir sur ce graph, c’est que les retards, c’est à dire les flux qui n’avait pas été mis à jours dans l’heure, ont fait un pic au moment de l’ajout des flux. Pic qui a eux quelques échos dans les heures suivantes. Ces échos ont finit par se tasser naturellement car, le crawler ne prends qu’un nombre limité de flux à rafraîchir et va donc, par construction, répartir la charge dans le temps.
À noter que même si les flux vont finir par se répartir dans le temps, la répartition ne sera jamais égale par la seule action du crawler (une évolution à venir ?). Pour remédier à ça, j’ai écrit un petit utilitaire qui répartira l’intégralité des flux.
Stress sur la base
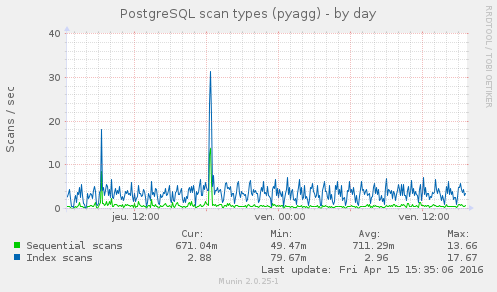
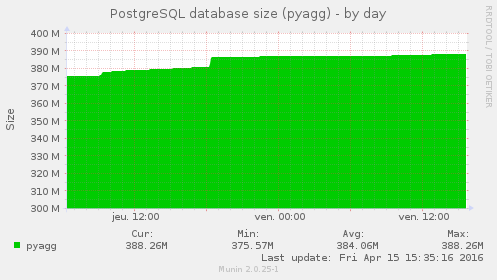
Bon, postgres a vaguement pris en poids au passage, mais ce n’est rien par rapport à la masse qu’il avait déjà (20M sur 400, moins de 5%) et même si le nombre de requête a explosé aux deux principaux imports de flux (j’imagine lors de l’import de fichiers OPML), tout est très vite revenu à la normal sans autres impact.
On peut observer que le nombre de flux a fait un cours bon à 600. C’est lors de ce pic que corresponds la prise de 10Mo de poids par la base, Ces flux ayant disparus, la base aurait du maigrir d’autant mais ce n’est pas le cas, je soupçonne une mauvais configuration qui empêcher le VACUM d’être éxécuté.
Stress sur la machine
Et pour finir voyons comment mon serveur s’est comporté :
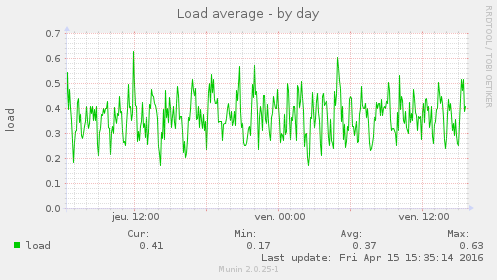
Mon server s’en fout ; il n’y a aucun impact sur la charge de la machine ni par le crawling ni par l’ajout massif d’articles.
Bon en même temps mon Xeon à 3.1GHz qui court à côté de s’est 4Go de RAM m’aurait fait bien de la peine à trimer pour si peu.
Conclusion
Certes, c’était un mini stress test sans grands enjeux mais je suis content de voir que JARR a bien tenu la charge.
Côté crawler, ça semble suffisament optimisé pour la tâche et le fait qu’il soit et multiprocess et multithreadé n’y est sûrement pas pour rien. Je ne pense pas avoir grand chose à améliorer de ce côté là.
Côté server, Postgres est largement suffisant pour la tâche (ce qui n’aurait probablement pas été le cas si j’étais resté sur un sqlite qui luttait déjà avec mon compte et ses 400 flux…). La machine est surdimenssionné aussi pour l’enjeux.
Côté applicatif, je ne sais pas. Je n’ai pas mesuré grand chose, mais vu l’impact sur le reste, je dirais que ça va. Le bench de ce côté là sera sûrement à prévoir pour une prochaine release ou une communication sur le projet via un média peut être plus important.