JARR v3
Posted on ven. 15 mai 2020 in misc
First of all, the new app is available here: app.jarr.info for you to test !
Preambule
JARR is a news aggregator and reader. JARR stands for Just Another RSS Reader and I’ve been personnally using and developing it for the past years.
After a v2 silently released several years ago, this time I’m making a true release. Before getting into the new things brought by this v3, I’ll talk a bit about what was brought by the precedent version. The v2 introduced very discretly and only by opting-in what I called clusters which are grouped articles.
Clusters
The root idea was that several feeds may reference a unique resource. On this base I implemented at the time a way to represent that in JARR. At each article creation, JARR will list the more or less recent user’s articles and will check if they do link to the same resource. If so, the newly created article will be added to the existing cluster, inheriting logically of its status (read or unread, liked or not).
The original goal was to reduce the meta-feed (the feed created by all the feeds of a user) by reducing redundancy. It’s very useful when subscribing to planets, news aggregator (like Hacker News) or even subreddits.
To add to this grouping processus only based on links, a colleague proposed to go further and to group articles based on their content so we would group article treating identical subjects. It’s done through tf-idf. It allows for example to group articles from national news outlet which are destined by essence to treat the same subjects.
Clusters: lesson learned
All of this was pretty experimental, and at the time I only put in place the one option to opt in or out. I rapidly discovered that :
-
A feed might always have one link, and only update the resource at the end of that link. This causes all the articles of that feed to get clustered together. The lesson from that is that a feed by feed control of the clustering is needed.
-
Filing the feeds under different categories allows, among other things, to mark as read entire categories. Clustering is independant from category and sometimes article from other categories that you wanted to read later got marked as read while marking a whole category as read. This implies two evolutions : it’s necessary to be able to deactivate clustering for a category and it’s necessary to be able to mark only article not belonging to clusters as read.
-
The reverse is also true, when clustering on an already read article happen, the new article won’t every be shown to the user. Knowing that we made it so that if an article is clustered with an article marked as read but not really read, JARR will change the read status of the whole cluster to unread. Like the rest this behavior can be disabled feed by feed.
-
The process in charge of refreshing feed in v2 did entierly by pushing HTTP request. As clustering can be a somewhat time consuming process, some problems occured :
-
Clustering, especially through tf-idf, was creating timeout errors
-
Several clustering process were executed in parallel. This meant that potentially, article were treated at the same time and missed each other when they should have been clustered together.
-
-
Introducing clusters to JARR brought a lot of complexity in the model. The most recurring complaint I got from users were that feed deletion began to take an awful lot of time. The new version bring a new workflows where, when deleted, a feed is hidden and removed by a background worker.
What’s new in JARR v3
Background workers
On very technical and backend point of view, the new version of JARR runs now on Docker. Three of them to be accurate : one to serv the Javascript UI, one to serv data to this UI and a last one which is a multitask background worker.
The last one runs a Celery worker which listens on a RabbitMQ queue.
Its main goal is to refresh feeds according to several configuration options. It has also the mission to cluster all pending articles. To avoid collision only one clustering process is ran by user at the same time. At last, the worker remove pending feed suppression. Indeed, to make the operation virtually instantaneous for the user, the deleted feed are merely hidden from the user and deleted in the background when the worker has time.
The user interface
I wrote the first version of the interface with React 0.14. I did let the project aside for a while and by the time I got back to it, React was already at version 14. Needless to say that the then-coded UI was not salvageable.
I just recently finished rewriting all from scratch. This time, with the idea of responsiveness and mobile devices in mind. Front-end not being among my strengths, I want to thank Clarisse without whom the interface would still look like bootstrap from 2015.
I also would like to thank another old colleague of mine, who made a very insightful code review. You have to pay attention to the details, but reading his review was enlighting to me.
Overall
Here’s a more exhaustive list of what has been done:
User eXperience:
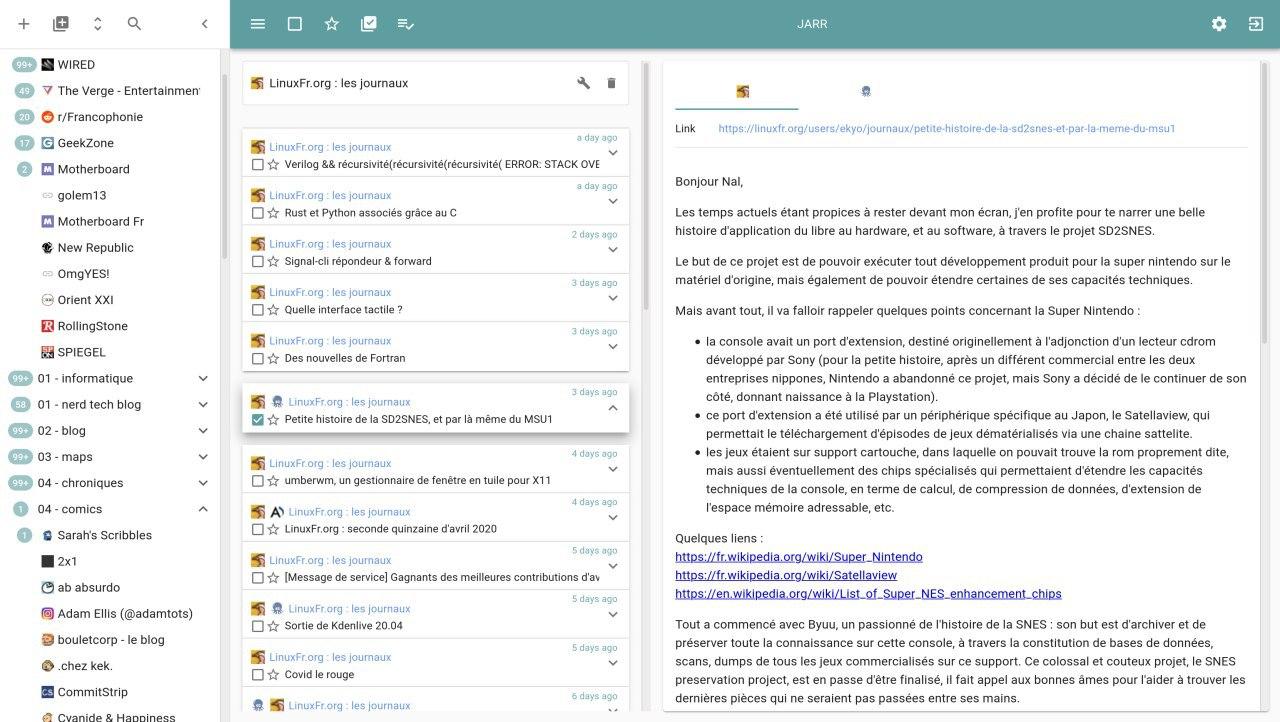
- A better interface for building and adding feeds.
Like in the v2, JARR is gonna try to construct a feed from any given URL (without scheme :
reddit.com/r/franceor even if the URL doesn’t link to a RSS or JSON feed :https://www.reddit.com/r/france). Not like in v2, this time the feed isn’t created as soon as the form is submited. Instead the feed is builded by the backend and sent back in a pre-filled form to the UI.
-
Change in the feed deletion processus: the feedback is now instantaneous and asynchronous.
-
Clustering option at feed, category and user level : It’s now possible to chose if the article from a feed, a category (or all the articles) can be clustered or not. It’s also possible to disable clustering through tf-idf and article wake up (marking a read feed as unread) by clustering.

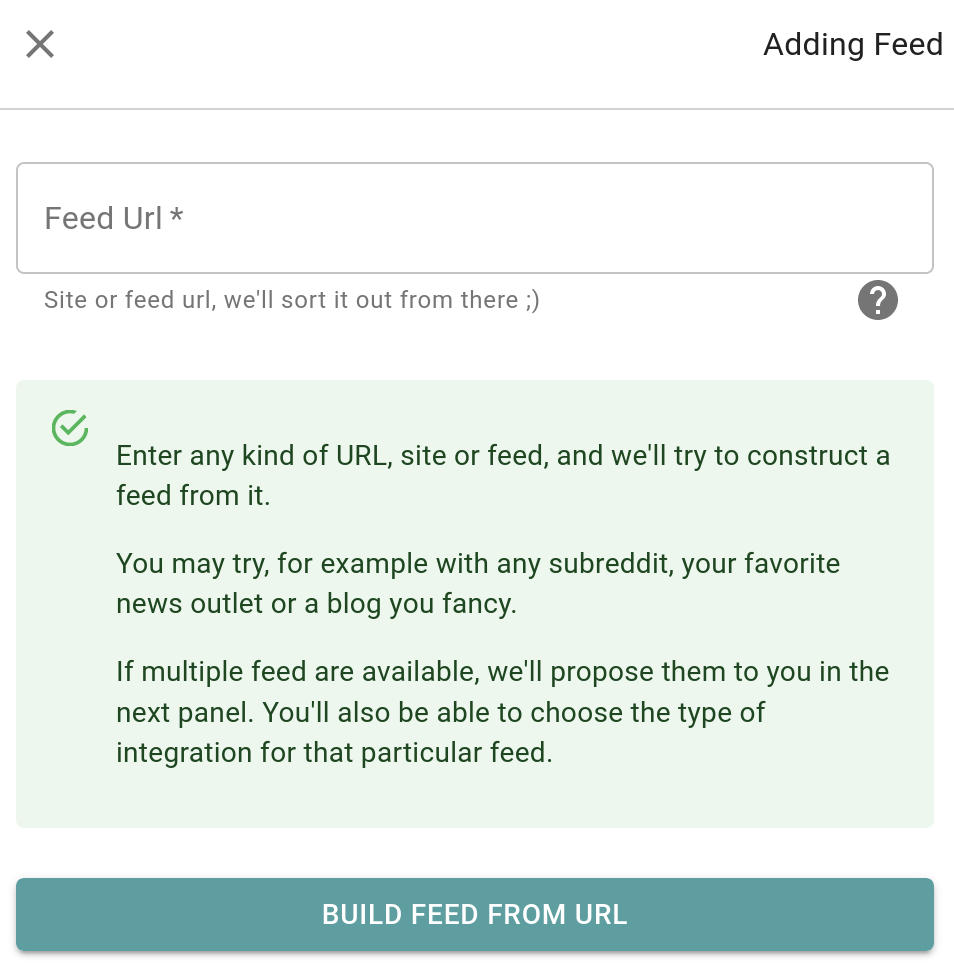
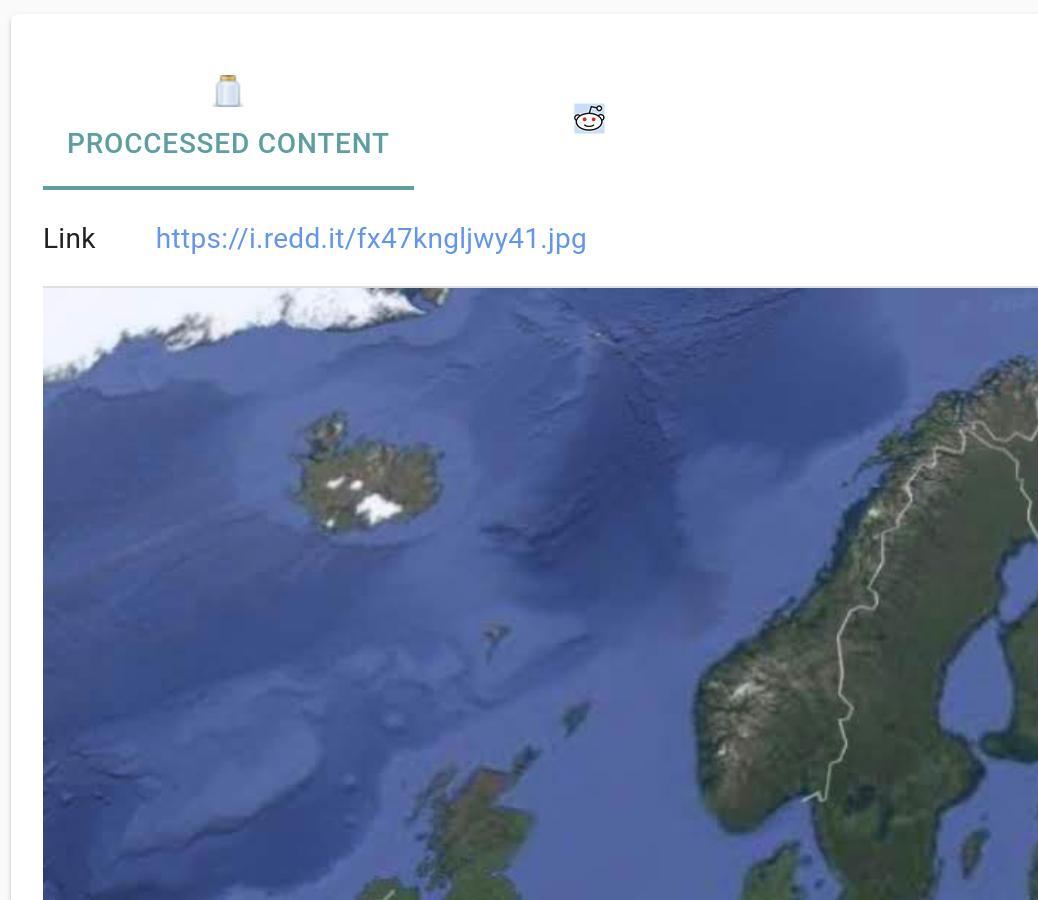
- Proccessed content integration (only for images of youtube link for now). If a type of supported content is recognized, JARR interface will create and integration for it.
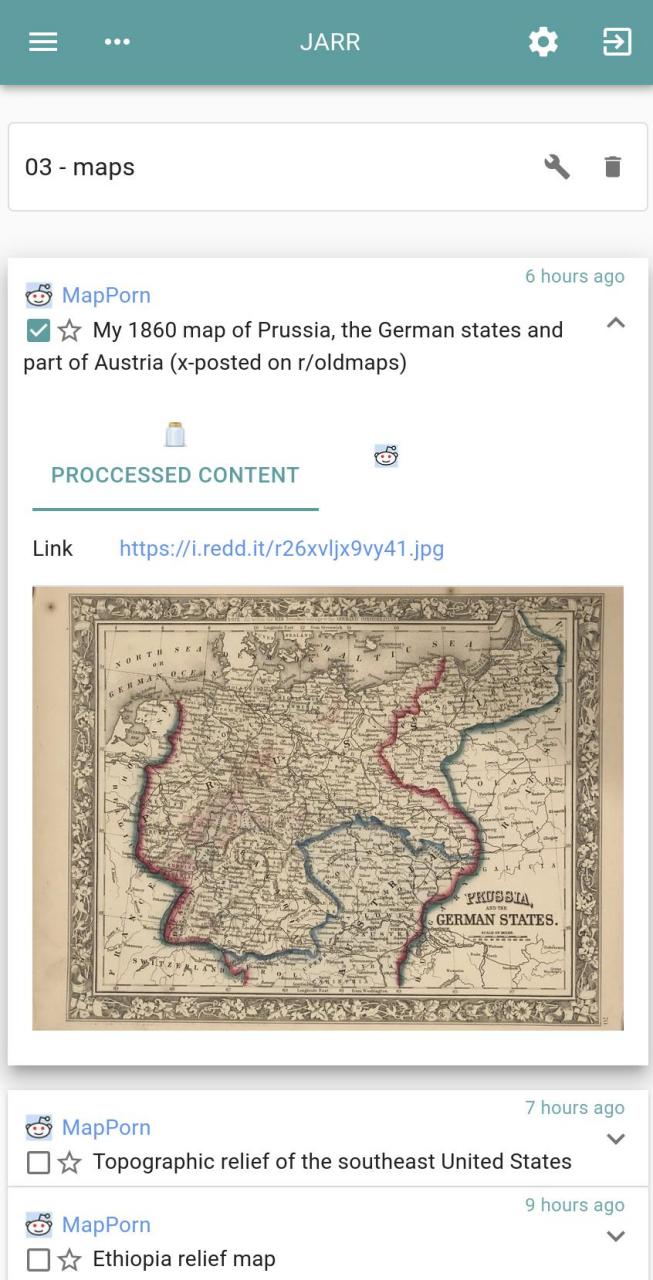
- Responsive design (feed menu can be hidden and article list comes in two versions: for large screen and for narrow ones).
- A limited integration with RSS-Bridge has also been realized so that JARR can figure out a way to serv content for website that doesn’t provide RSS feed. For now, only Twitter, Instagram and Soundcloud are supported.
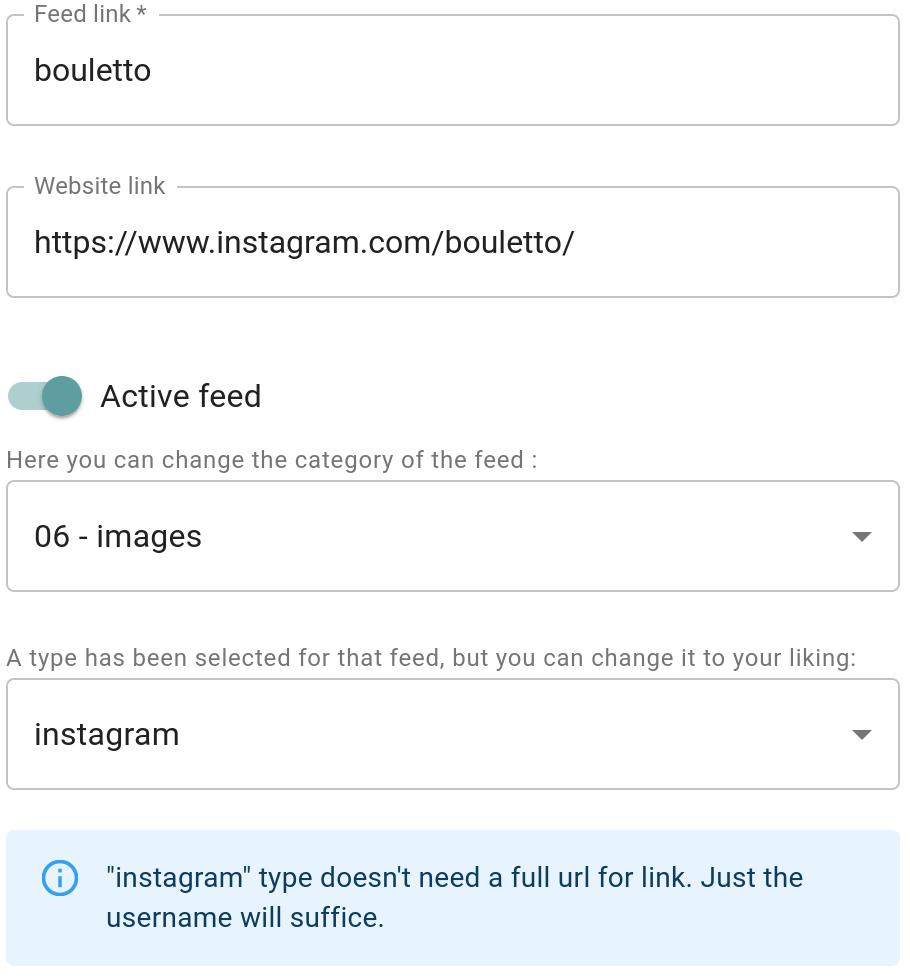
- Edition in a dedicated panel for feed, categories, and user settings.
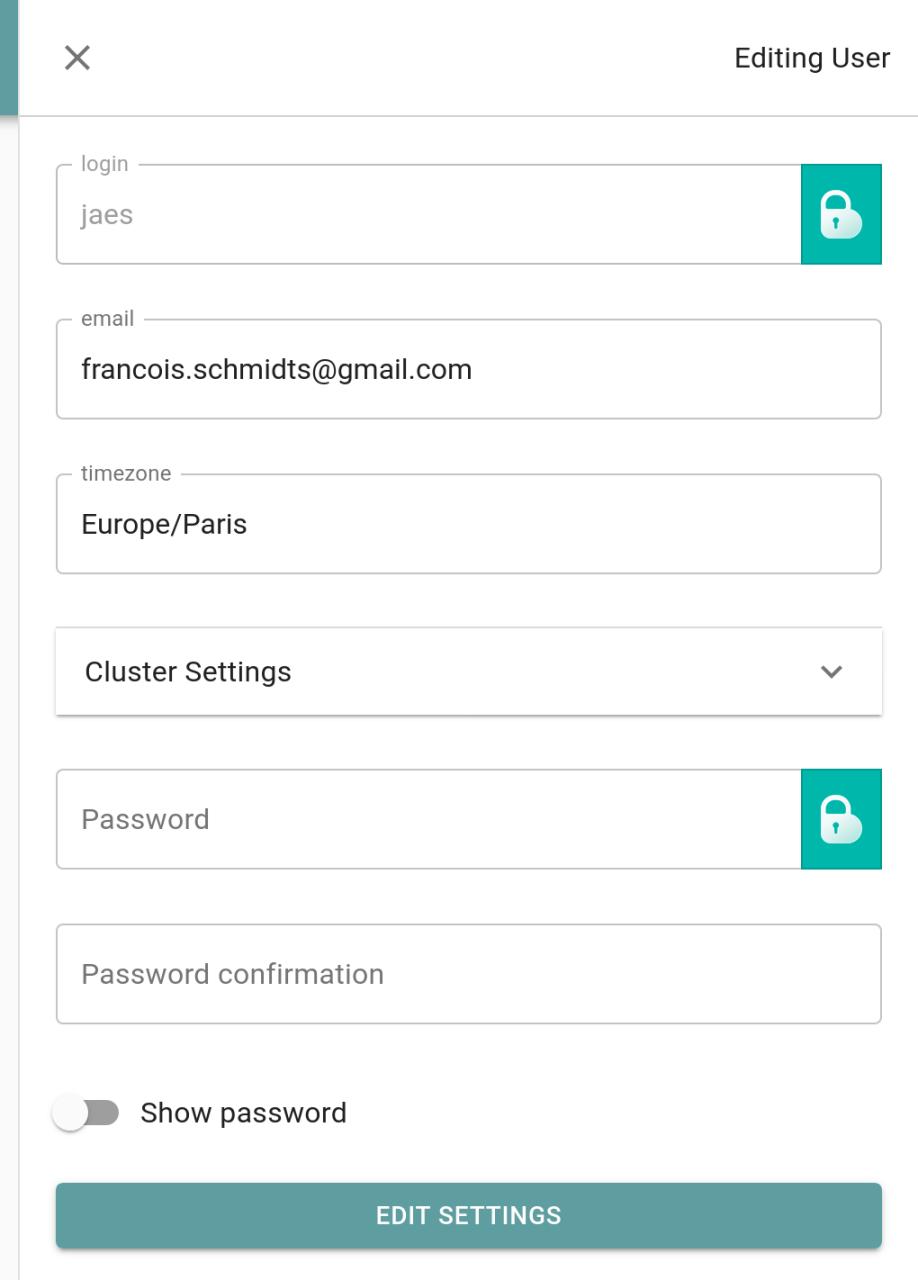
Server side:
- From scratch rewrite of the API through Flask-restx
- API accessible via Swagger at api.jarr.info
- Removing of a lot of dead code and dependencies
- Json feeds are now supported
- Total rewrite of the crawler
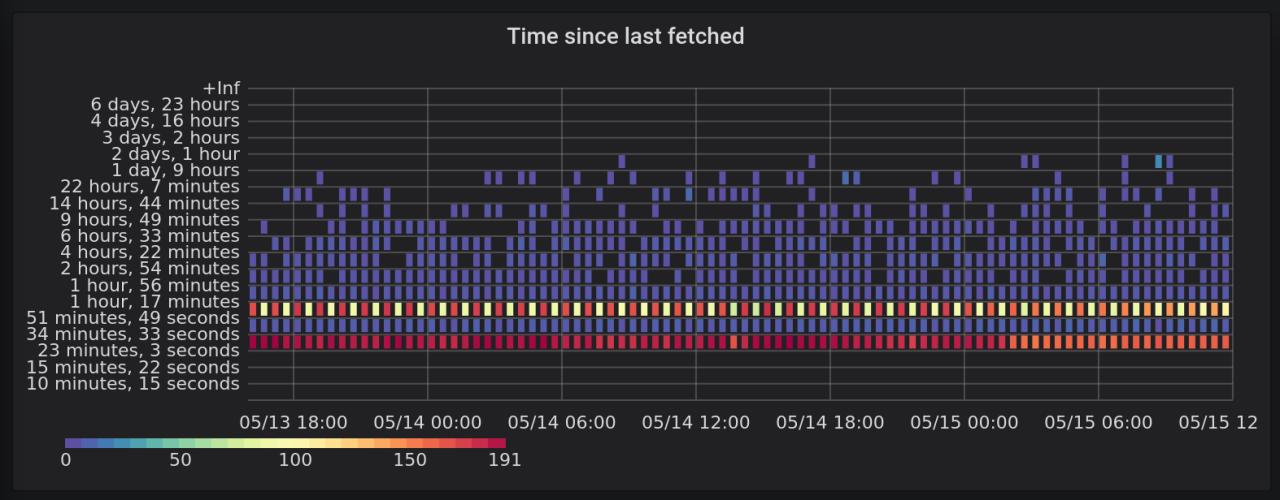
- Drop of munin integration for a prometheus one
This last point allows me, among other things, to see globally how JARR handles freshness of feeds :
What’s to come
Of course, development continues ! In priority (for the v3.1), I’ll work on features present in v2 and missing for v3:
I still have a lot of ideas for new functionalities like orderable and drag-n-dropable categories.
I am also of course open to suggestions. Don’t hesitate to comment below or open an issue on the bug tracker if encounter any problem or whish for a new functionality.