JARR v3
Posted on ven. 15 mai 2020 in JARR
Avant toute chose, voici le lien vers la nouvelle version de l’application : app.jarr.info
Préambule
JARR est un aggrégateur et un lecteur de flux. JARR signigie Just Another RSS Reader et je l’utilise et l’entretient depuis maintenant plusieurs années.
Après une v2 sortie silencieusement il y a quelques années, cette fois ci je fais une vrai release pour marquer le coup. Avant de m’étendre sur les nouveautés apportés par cette v3 je vais revenir un peu sur la version précédente. La v2 apportait très discrètement et seulement en opt-in ce que j’ai appelé les clusters : des groupements d’articles.
Les clusters
L’idée de base étant que plusieurs flux peuvent référencer une même ressource, j’ai implémenté à l’époque les models et l’interface pour représenter cela. À chaque création d’article, JARR list d’autres articles plus ou moins récents de l’utilisateur et vérifiera s’ils ne pointent pas vers la même ressource. Si c’est le cas le nouvel article sera rajouté au regroupement d’un article existant, héritant de fait de son statut (lu / non lu, marqué comme favoris ou non).
Le but premier de la manœuvre étant de réduire un méta-flux (l’ensemble de tous les flux d’un utilisateur), dont le débit peut être important, en éliminant la redondance. C’est particulièrement utile quand on souscrit à des planet ou autres aggrégateurs de flux (comme Hacker News ou sa contrepartie française le journal du hacker) et même des subreddit.
Pour rajouter à ce groupement basic, uniquement basé sur les liens, un collègue m’a alors proposé d’aller plus loin et de permettre de regrouper des articles parlant de la même chose via TF-IDF. Cela permt de réduire le méta flux créé par plusieurs journaux nationnaux, par exemple, qui traiteraient des mêmes nouvelles.
Les clusters : retour d’expérience
Tout cela était plutôt expérimental, je n’ai à l’époque mis qu’une seule option pour activer ou non le regroupement. En effet on s’aperçoit assez rapidement que :
-
Certains flux renvoient toujours le même lien et mettent à jours la ressource au bout du lien (par exemple vigicrues). Par conséquent l’intégralité du contenu de ce genre de flux sera regroupé en un seul article. Il est donc nécessaire de pouvoir désactiver le groupement flux par flux.
-
Classer ses flux en catégorie permet, entre autre, de marquer comme lu (ignorer le contenu) de plusieurs flux à la fois. Le regroupement d’article étant indépendant des catégories, il arrive que des articles d’autres catégories soient ignorés dans le processus. Il est donc nécessaire de pouvoir désactiver le groupement pour toute une catégorie. Il est aussi nécessaire de pouvoir marquer comme lu uniquement les articles qui ne font pas parti d’un groupement.
-
L’inverse est aussi vrai, le regroupement se faisant sur un article déjà lu, le groupement restera invisible car déjà lu. Par défaut, si un article a été marqué comme lu sans être lu et qu’il est groupé avec un nouvel article, son status lu est changé à non lu. Comme le reste ce comportement est désactivable flux par flux.
-
Le fonctionnement de l’époque était tout en HTTP synchrone. Le crawler envoyait une requête et le serveur web créait le nouvel article et faisait le groupement ce qui a plusieurs désavantages :
-
Le groupement, surtout via TF-IDF, est un processus long (potentiellement trop) pour le contexte d’une requête web.
-
Par définition, plusieurs groupements peuvent être exécutés en parallèle ce qui laisse la possibilité que des articles qui, créés en même temps et qui auraient dû être regroupés ensemble ne le soient pas.
-
-
L’introduction des groupements d’article a apporté son lot de complexité. La remontée la plus fréquente a été que la suppression d’un feed était devenu très longue. La suppression a donc été rendu asynchrone et est faite par un processus d’arrière plan.
La v3 : ce qui est nouveau
Worker en arrière plan
D’un point de vu très technique et backend, la nouvelle version de JARR tourne maintenant via Docker. Trois pour être précis, un qui sert le Javascript pour l’interface utilisateur, un pour servir les données à cette interface utilisateur et un worker d’arrière plan multi fonction.
Ce dernier lance un worker Celery qui écoute sur une base RabbitMQ.
Son but principal est de rafraichir les flux selon plusieurs options de configuration (délai minimal et maximal de rafraîchissement entre autre). Ensuite, pour chaque utilisateur, de créer les groupements pour tous les articles qui en sont dépourvus. Enfin, il s’occupe de la suppression des flux marqués à supprimer. Pour rendre l’opération instantanée pour les utilisateurs, les flux à supprimer sont en effet simplement cachés en attendant que le worker passe pour faire le ménage.
L’interface
J’ai écrit la première interface de JARR sur React 0.14, le temps de m’occuper d’autre chose, react en était déjà à sa version 14. Autant dire que l’ancienne interface était irrécupérable.
J’ai donc entrepris de tout réécrire de zéro, avec cette fois à l’idée une interface compatible avec les smartphones. Le front n’étant pas mon cœur de métier, je tiens à remercier Clarisse sans qui l’interface ressemblerait toujours à du bootstrap de 2015.
Je tiens aussi à remercier un autre ancien collègue qui m’a apporté une code review des plus instructives. Comme d’habitude il faut se pencher sur les détails mais j’ai eu révélation sur révélation en relisant mon code et en comparant avec les points d’amélioration).
D’un manière générale
Pour faire une liste plus exhaustive de ce qui a été amélioré :
Expérience utilisateur :
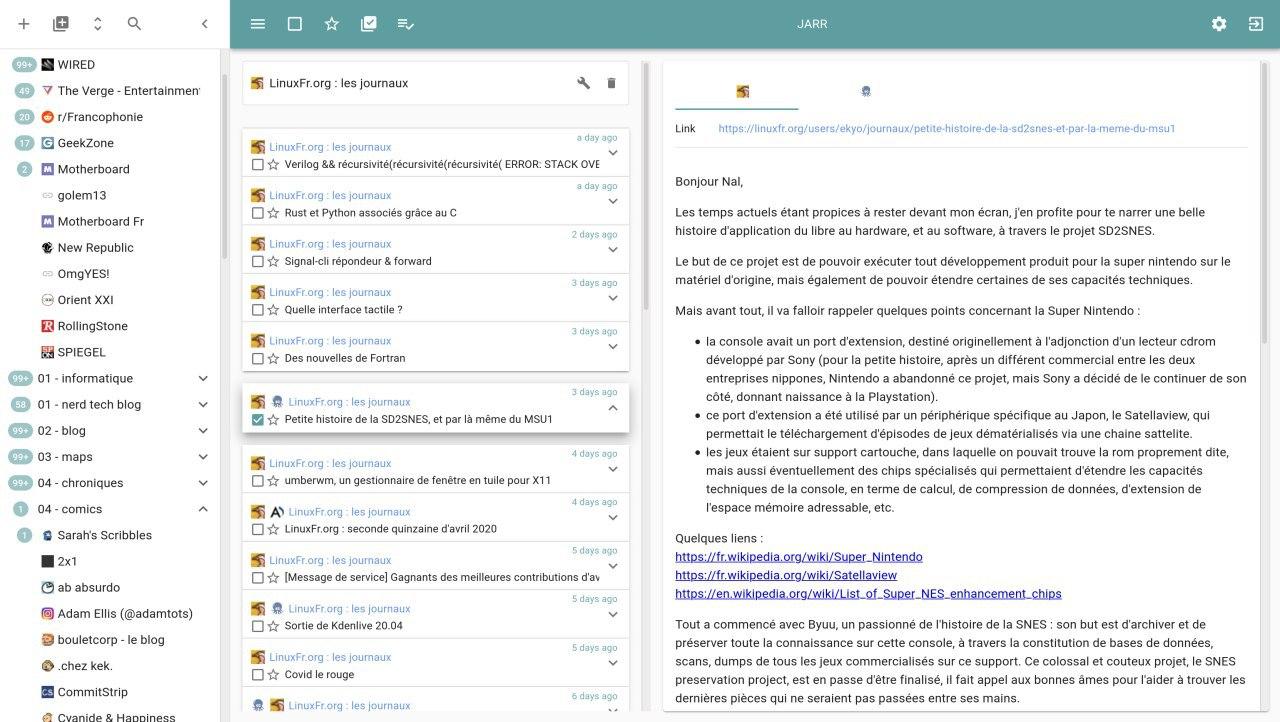
- Meilleur interface pour l’ajout de flux RSS.
Comme pour la v2, JARR va tenter de construire un flux RSS à partir de n’importe quelle url (même si le protocol est manquant :
reddit.com/r/france, ou même si la ressource n’est pas un flux RSS :https://reddit.com/r/france/). À la différence de la v2, le flux n’est pas créé immédiatement mais un panneau avec le flux préconstruit est affiché de sorte que l’utilisateur puisse l’éditer avant de le créer.
-
Modification de la suppression de flux : la suppression est maintenant instantanée et asynchrone
-
Option de contrôle du groupement d’article au niveau flux, catégories et utilisateur. Il est désormais possible de choisir si les articles d’un flux, d’une catégorie (ou même tous les articles) peuvent être groupé. Il est aussi possible de désactiver le groupement par TFIDF et le réveil (le marquage comme non lu lorqu’il est lu) d’un article par le processus de groupement.

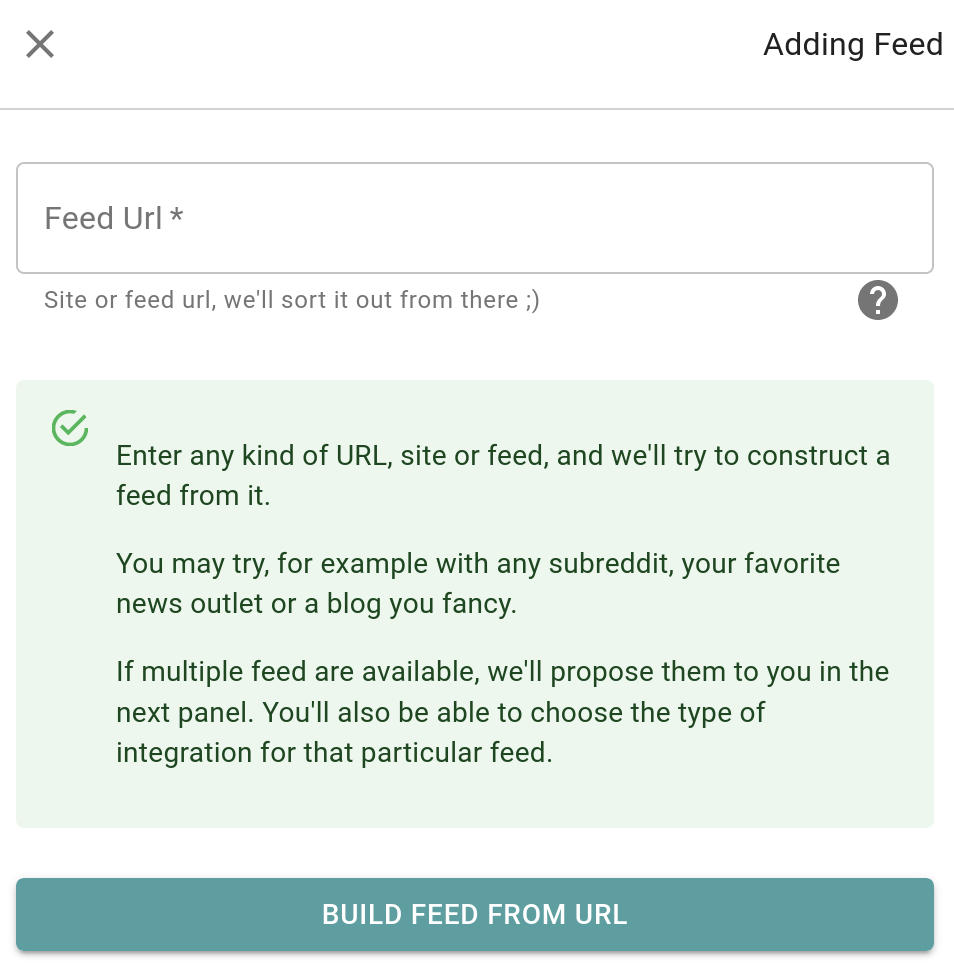
- Intégration sur mesure (pour l’instant seulement si la ressource pointent vers une image ou une vidéo youtube). Si un type de contenu supporté est reconnu, l’interface de JARR créra une intégration sur mesure.
- Interface responsive (le menu des flux est repliable et la listes des articles a deux versions : pour les écrans larges et étroits).
- Intégration limité avec RSS-Bridge afin de fournir des flux RSS pour des site qui en sont dépourvus. Sont supporté automatiquement pour l’instant Twitter, Instagram et Soundcloud.
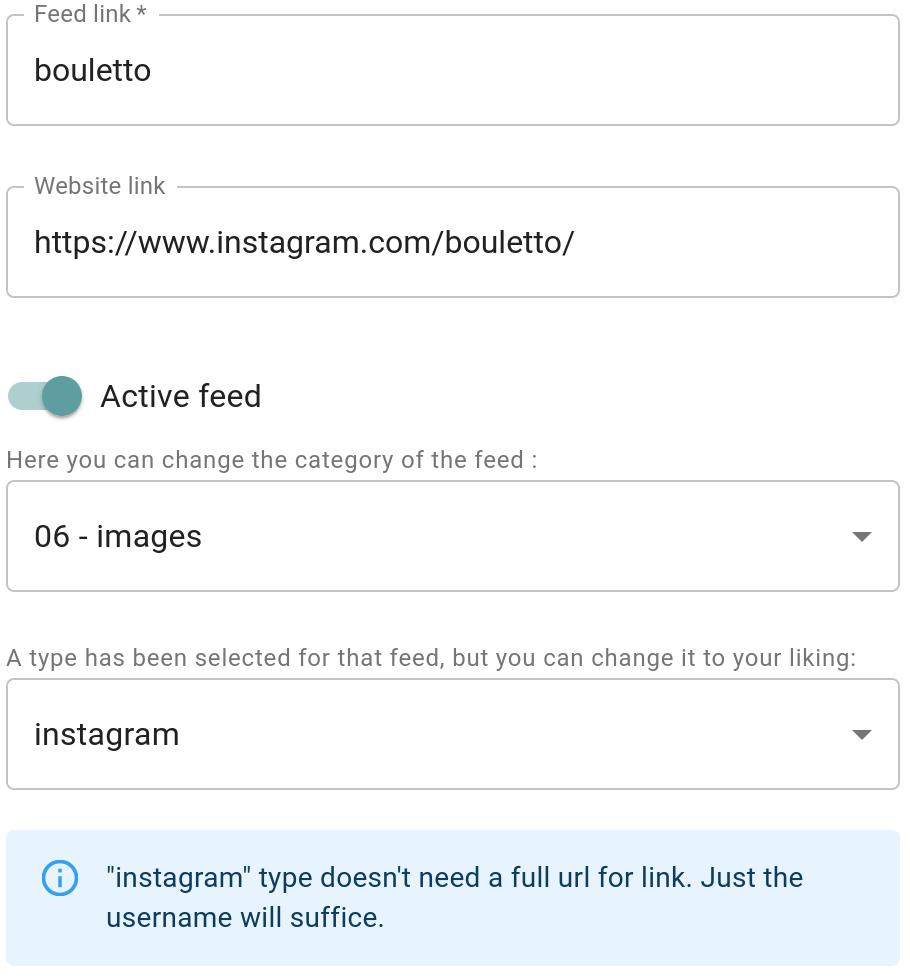
- Édition dans un panneau dédié des options des flux, catégories et de l’utilisateur
Côté server :
-
Refonte totale de l’API via Flask-restx
-
API accessible via Swagger sur api.jarr.info
-
Suppression de beaucoup de code mort
-
Support des flux Json
-
Refonte totale du crawler, plus facilement intégrable avec d’autres types de resources
-
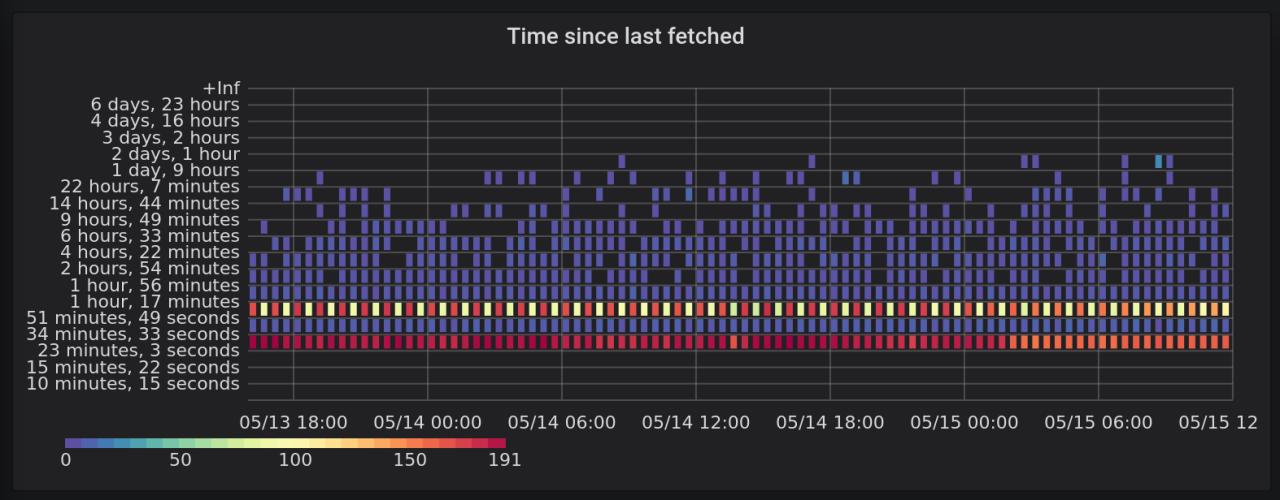
Abandon de munin pour un plug prometheus
Ce dernier point me permet entre autre de voir d’une façon globale, comment l’application gère le cache et les délais entre deux rafraîchissement d’un flux :
À venir
Bien entendu ce n’est pas fini et le développement continu. En priorité (pour la v3.1) j’implémenterai des fonctionnalités présentes dans la v2 mais absente de la v3 (par soucis de temps). Entre autre :
J’ai aussi quelques idées de fonctionnalités comme rendre drag-n-dropable les catégories et pouvoir les ordonner à la main.
Je suis bien entendu ouvert aux suggestions. N’hésitez pas à commenter ou à ouvrir une issue sur le bug tracker si vous rencontrez un problème ou souhaiteriez une nouvelle fonctionnalité.